
Hello, I'm Pavan Pandya. I'm driven by curosity and a passion for solving real world problems through technology.
About me
With a background in Computer Science, I’ve built and shipped AI-powered full-stack applications across startups, research labs, and consulting. What drives me is the challenge of turning ideas into scalable products, whether that means architecting reliable backend systems, crafting clean user interfaces, or automating infrastructure. My core stack includes Python, React, Node.js, Django, Flask, and PostgreSQL, and I’m experienced with AWS, Docker, Kubernetes, and CI/CD pipelines. I’m currently seeking a full-time Software Engineer role where I can contribute end-to-end and make an impact.
Outside of coding, I enjoy experimenting in the kitchen and taking long walks with music or podcasts, great ways to recharge and spark fresh ideas. I thrive on collaboration and continuous learning, and I’m always excited to build meaningful products alongside great teams.
Education
Indiana University Bloomington
Master of Science in Computer Science
Bloomington, IN
- Relevant Coursework: Applied Algorithms, Computer Networks, Deep Learning Systems, Applied Machine Learning, Software Engineering - I, Engineering Cloud Computing, Information Visualization, Elements of Artificial Intelligence, Introduction to Statistics
- Graduated with GPA: 3.7 / 4.0
LDRP Institute of Technology and Research
Bachelor of Engineering in Computer Engineering
Gandhinagar, India
- Relevant Coursework: Software Engineering, Design & Analysis of Algorithms, Computer Networks, Database Management Systems, Web Development, Artificial Intelligence, Object Oriented Programming, Data Structure and Algorithms, Python, Machine Learning, Soft Computing, Natural language processing, Image Processing, Optimization Techniques
- Graduated with CGPA: 9.1 / 10.0
My projects
Flagship
Engineered a distributed feature flag system to enable teams to safely turn features on/off without redeploying code, creating a full-stack solution and Prometheus for monitoring.
- Golang
- React
- Node.js
- Python
- Kubernetes
- Prometheus
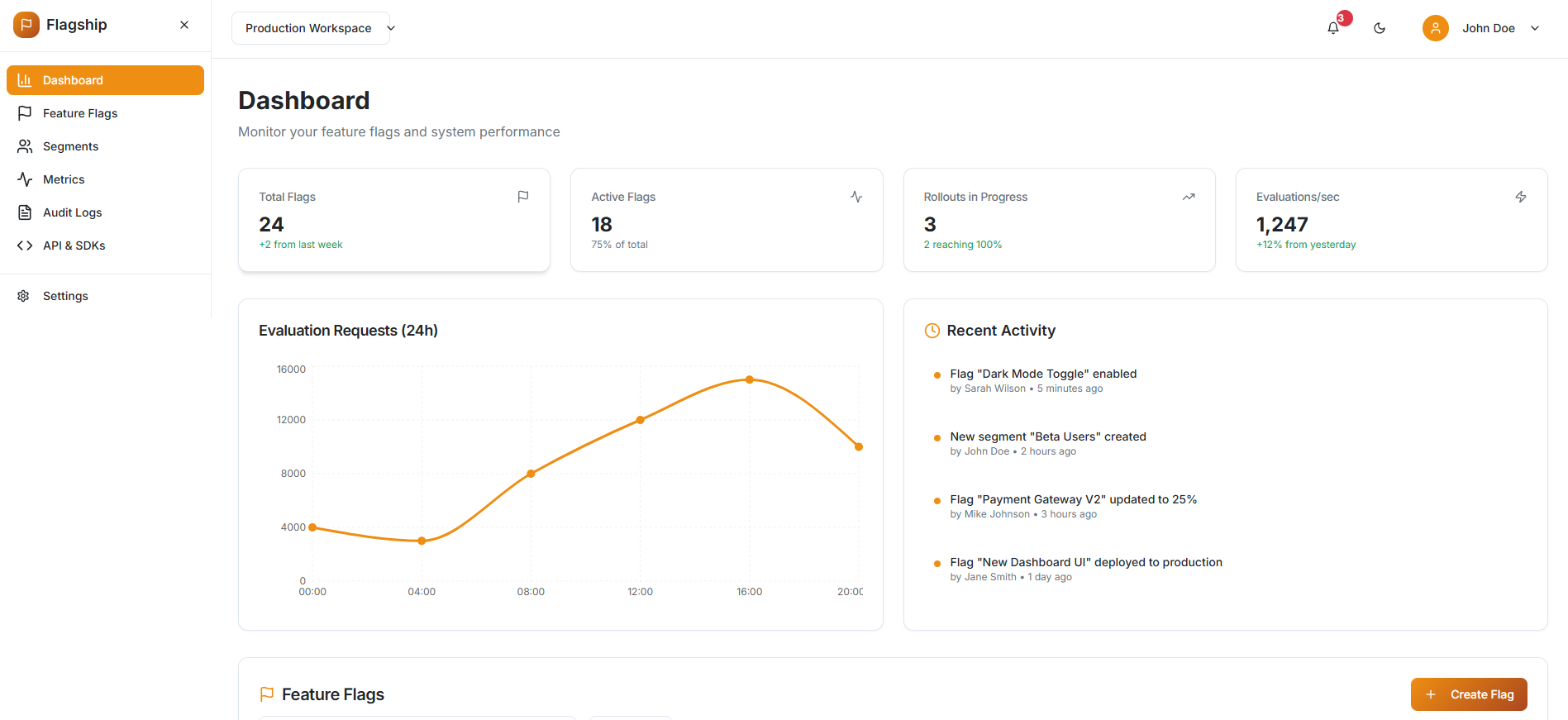
IU Course Compass
An AI-powered course planner that generates personalized recommendations by analyzing historical grade data and professor ratings to help them make informed academic decisions.
- React
- TailwindCSS
- FastAPI
- Supabase
- Gemini AI
Itinera - Full Stack AI Travel Planner Application
Developed a full-stack travel planning app that provides personalized recommendations and real-time data synchronization, enhancing the user experience with AI-driven features and secure cloud-based services.
- React
- Gemini AI
- TailwindCSS
- Firebase

Optimized NSFW Content Detection for Real-Time Moderation
Developed an NSFW content detection model using ResNet18, achieving 95.1% accuracy and optimizing model size and inference speed for real-time moderation on resource-constrained devices.
- PyTorch
- CNN
- Deep Learning
- Quantization

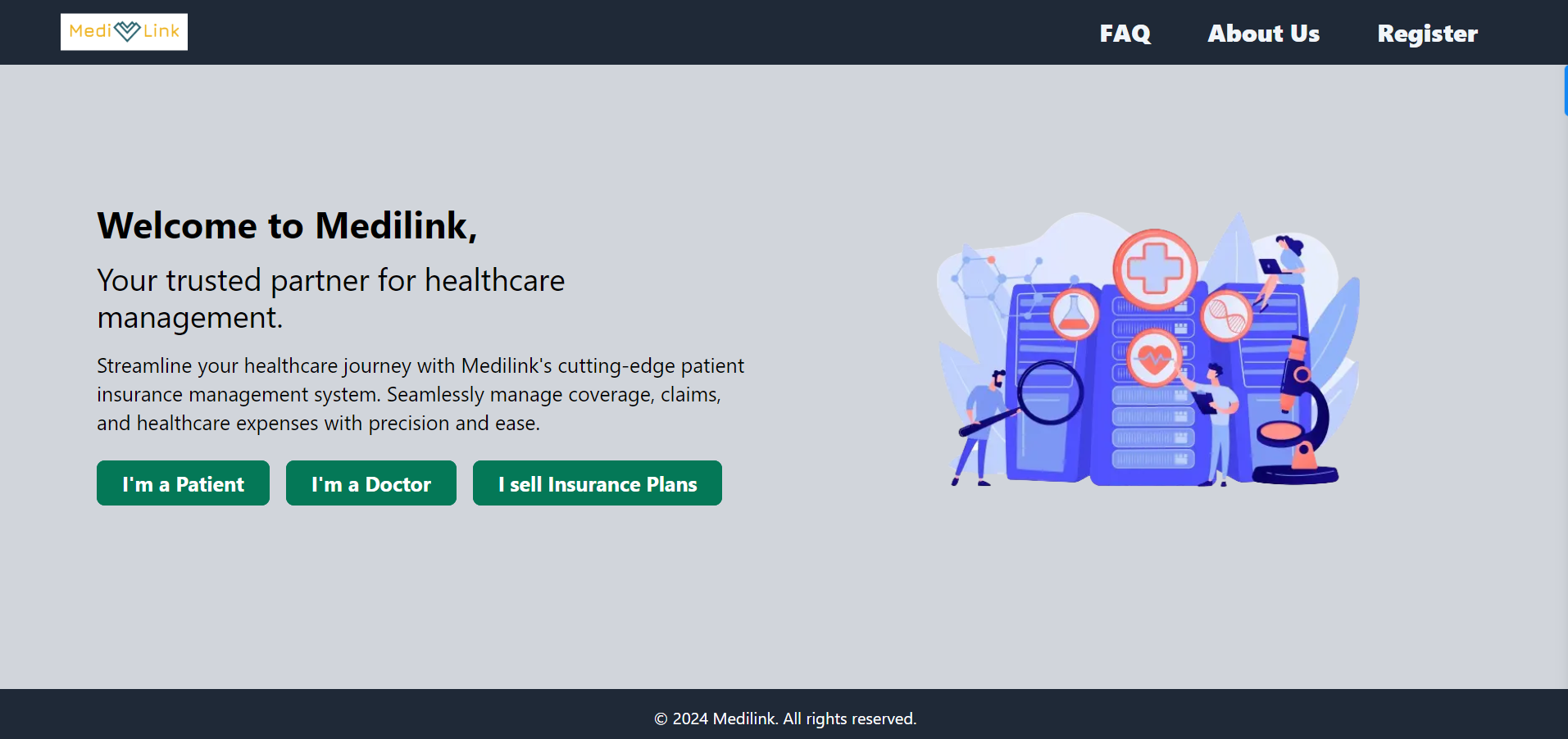
MediLink - Patient and Insurance Management System
As a full-stack developer, I developed a healthcare management platform enabling patients, doctors, and insurance providers to efficiently manage appointments, medical records, and insurance plans.
- Django
- Next.js
- Render
- PostgreSQL
- Docker
Unveiling Trends - A Cloud-Driven Data Engineering Project
I created a custom YouTube data scraper and built interactive QuickSight dashboards to analyze and visualize trending topics, supporting informed decision-making.
- AWS
- S3
- Glue
- Lambda
- Athena
- QuickSight
- Python
My skills
- Python
- JavaScript
- TypeScript
- SQL
- React
- Next.js
- HTML
- CSS
- Tailwind CSS
- Node.js
- Express.js
- Flask
- Django
- FastAPI
- RESTful APIs
- GraphQL
- Microservices
- AWS
- Azure
- Firebase
- Supabase
- NeonDB
- PostgreSQL
- MySQL
- MongoDB
- DynamoDB
- Redis
- Elasticsearch
- Git
- Linux
- GitHub Actions
- CI/CD
- Docker
- Kubernetes
- Terraform
- Selenium
- Jest
- PyTest
- Postman
- Swagger
- Render
- Railway
- Vercel
- Jira
- Agile
- Scrum
- SDLC
- Unit Testing
- Integration Testing
- Power BI
My experience
Offline Talent
Product Engineer
Chicago, IL
- Engineered the MVP of a marketing discovery platform for brands to execute in-person campaigns at scale through a network of 10,000+ IRL communities, delivering the application in 5 weeks by building 30+ components with React and TypeScript.
- Architected the core backend system by designing 33+ RESTful API endpoints with server-side pagination in Node.js, supported by a scalable PostgreSQL schema on Neon DB to ensure efficient data handling for 10,000+ communities.
- Drove product velocity by establishing a comprehensive testing suite with Jest (unit) and Postman (API) and leveraging AI-powered tools, enabling an automated CI/CD pipeline for rapid deployments to Vercel and Railway.
Heartland Community Network
Senior Consultant – Software Engineer (Contract)
Remote
- Led and developed an Advertising Marketplace platform from ideation to first launch by running client workshops to define product scope, translating business requirements into Jira stories and aligning stakeholders and engineers for faster delivery.
- Developed core product features in React, integrating REST APIs and collaborating with product manager, engineers and designers to deliver a user-focused solution, supporting business goals and ensuring reliable performance through Postman API testing.
- Architected a backend system using Node.js with optimized SQL database schemas and REST APIs, applying MVC design architecture to create a maintainable platform that supports future scalability and smooth feature expansion.
Marchup Inc.
Software Developer Intern
San Jose, CA
- Designed and launched an AI-powered counseling chatbot using Python (Flask) and Azure OpenAI, providing real-time personalized guidance to students and parents and improving session satisfaction by 20% as measured through surveys.
- Optimized chatbot performance with Redis caching and asynchronous processing to deliver sub-second responses to concurrent users and introduced a dual-mode logic flow (static for FAQs, generative for new queries) that saved $600/month in cloud costs.
- Developed two key engagement features - an adaptive AI to generate contextual follow-up questions and a user recommendation engine using Elasticsearch and cosine similarity to connect users, driving higher daily engagement.
- Automated document updates with AWS Lambda (Python Script) and implemented system health monitoring via CloudWatch during migration to AWS OpenSearch, improving search accuracy and ensuring stable performance for 10,000+ documents.
- Automated deployments to AWS ECS Fargate using CDK and Docker, worked cross-functionally to integrate CI/CD pipelines with Pytest for unit and integration testing and performed 20+ peer code reviews to ensure high code quality and reliable releases.
Dhirubhai Ambani University
Data Science Intern
Gandhinagar, India
- Enhanced model performance by 15% by fine-tuning a BERT-based multilingual model using pseudo-labeling techniques, leveraging data for hate speech detection, and optimizing it with few-shot learning for low-resource languages.
- Increased annotation throughput by 40% by developing a REST API backend that streamlined participant submissions and introduced dynamic dashboard filtering by task accuracy and categories, enabling faster and more efficient workflows.
- Automated Twitter data scraping and built preprocessing pipelines, reducing weekly maintenance by 80% (10 to 2 hours) by cleaning and structuring 10K+ tweets and developing REST APIs with unittest coverage for submission and registration workflows.
Hate Speech and Offensive Content Identification
Data Science Intern
Gandhinagar, India
- Built a full-stack competition platform that automated submission evaluation and leaderboard updates using Python and JavaScript, increasing participation by 40% and reliably handling 500+ entries across 15+ teams.
- Developed a registration portal with JavaScript, HTML/CSS and GCP storage, enabling participants to register and upload documents directly, while giving organizers an admin panel for document verification, cutting onboarding time by 67% from 15 to 5 mins/user.
- Automated Twitter data scraping and built preprocessing pipelines, reducing weekly maintenance by 80% (10 to 2 hours) by cleaning and structuring 10K+ tweets and developing REST APIs with unittest coverage for submission and registration workflows.
Contact me
Please contact me directly at pavanpandya.iu@gmail.com or through this form.